🌟 Highlight
Based on this blog post , got an opportunity to give a talk based on Simplicity & Effectiveness of Byte Pair Encoding (BPE). Here is the link to the talk :🎙️ Cohere for AI
Imagine teaching a kid to read and understand text. Chances are we start with individual letters, then combine them individually and let the child read. Then over time, you see the dividends right in front of you. The child becomes proficient in reading by combining words of various syllables. Coming to a machine, again the same process is repeated. You need a set of rules, a way to break down the text into manageable chunks. I’ll be calling Byte Pair Encoding by its more compact nickname, BPE, throughout this post—because who has the time to type out long names when we can just use the cool acronym.
At its core, BPE is about finding patterns in text ,more about figuring out which patterns are worth remembering. Let’s break it down. When you take a look at paragraph of text, there are certain pairs of characters that appears together quite often. For instance, in English, “th” is a common pair, as is “in” and “ed.” BPE takes this observation and turns it into a strategy for text processing.
To visualize the BPE process, think about the game Tetris, where players complete lines by strategically placing differently shaped pieces. Similarly, in BPE, you start with individual characters or bytes as building blocks. These blocks are combined one by one based on their frequency of occurrence, much like how Tetris pieces are used to complete lines. Each merge of a pair of characters creates a new “block” that represents a larger piece of the vocabulary.
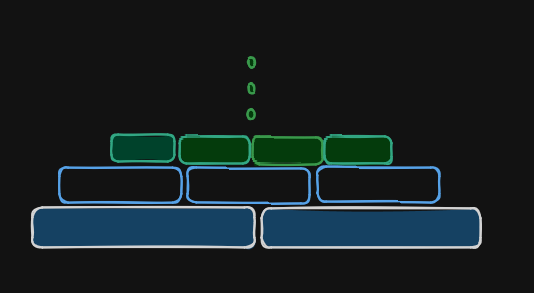
Over time, these blocks represent larger and more complex patterns in the text. The goal is to efficiently represent the information needed to express the text, much like how completed lines in Tetris efficiently clear space. By iteratively merging the most frequent pairs, BPE helps build a vocabulary that strikes a balance between too many tokens and too few.
The beauty of BPE lies in its simplicity and effectiveness. Now let us try to implement it in C , Andrej Karpathy has already implemented it in python and I’m not here to challenge the master rather see if it can be implemented in C . I’m quite rusty about writing this in C , but yet lets march forward. Do let me know if you spot any errors.
Setup
Header libraries which we need for the implementation. These libraries are necessary for handling input output stream , string functions and memory allocation.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>Since this is a minimal implementation of BPE, I’m assuming the vocabulary size to be 256 and the maximum text that it can handle up to 1024 characters.
#define INITIAL_VOCAB_SIZE 256
#define MAX_TEXT_SIZE 1024The next goal is to set a few data structures to handle the operations that would take place down the line
typedef struct {
int first;
int second;
} IntPair;
typedef struct {
IntPair pair;
int idx;
} Merge;
typedef struct {
Merge *merges;
size_t num_merges;
unsigned char **vocab;
size_t vocab_size;
} BasicTokenizer;IntPair- represents a pair of tokensMerge- represents a pair of tokens being merged and an integeridxfor the index of the new token in the vocabularyBasicTokenizer- defines the main tokenizer class consisting of the merges, the number of merges to be performed, vocabulary, and the size of vocabulary as its attributes.
A simplified overall flow of the process will be
- Encode the input text
- train the tokenizer
- merge operations take place
- decode the encoded text
If you prefer to code along or feel like modifying the implementation, feel free to fork my repository
Now lets break it down one by one , first we will initialize the tokenizer
BasicTokenizer* create_tokenizer() {
BasicTokenizer *tokenizer = (BasicTokenizer*)malloc(sizeof(BasicTokenizer));
tokenizer->merges = NULL;
tokenizer->num_merges = 0;
tokenizer->vocab = (unsigned char**)malloc(INITIAL_VOCAB_SIZE * sizeof(unsigned char*));
for (int i = 0; i < INITIAL_VOCAB_SIZE; ++i)
{
tokenizer->vocab[i] = (unsigned char*)malloc(sizeof(unsigned char));
tokenizer->vocab[i][0] = i;
}
tokenizer->vocab_size = INITIAL_VOCAB_SIZE;
return tokenizer;
}here we get to assign an empty merge list and a vocab containing the first 256-byte values
Since we are implementing this in C, memory management needs to be done manually and is important, hence we need to write a function to clean the memory used. The goal is to free the memory allocated for the tokenizer, this includes the vocab array, the merges, and the tokenizer structure itself. While we can’t directly observe the memory being freed in our output, this function is crucial for preventing memory leaks in our program.
void clean_tokenizer(BasicTokenizer *tokenizer) {
for (size_t i = 0; i < tokenizer->vocab_size; ++i) {
free(tokenizer->vocab[i]);
}
free(tokenizer->vocab);
free(tokenizer->merges);
free(tokenizer);
}now let us write a simple main function to see if it works properly
int main() {
BasicTokenizer *tokenizer = create_tokenizer();
printf("Tokenizer created.\n");
printf("Vocabulary size: %zu\n", tokenizer->vocab_size);
clean_tokenizer(tokenizer);
printf("Tokenizer cleaned.\n");
return 0;
}And it does , here is the output for your reference
Tokenizer created.
Vocabulary size: 256
Tokenizer cleaned.Training
We will now proceed to create the core functionality of our code , where we train our tokenizer. The train function needs to perform byte pair encoding on the input text by learning the merges . We also need few more functions that can assist this process namely - token_counts - counts the occurrences of each pair of tokens - merge - merges the tokens and updates the array with new token index - find_pair_index - finds the index of a specified pair in the merges array.
void token_counts(const int *ids, size_t ids_size, size_t *pair_counts, size_t *pair_counts_size) {
*pair_counts_size = 0;
for (size_t i = 0; i < ids_size - 1; ++i) {
IntPair pair = { ids[i], ids[i + 1] };
size_t index = find_pair_index((Merge *)pair_counts, *pair_counts_size, pair);
if (index == *pair_counts_size) {
// New pair
pair_counts[*pair_counts_size * 3] = pair.first;
pair_counts[*pair_counts_size * 3 + 1] = pair.second;
pair_counts[*pair_counts_size * 3 + 2] = 1; // Initialize count to 1
(*pair_counts_size)++;
} else {
// Increment count
pair_counts[index * 3 + 2]++;
}
}
}
void merge(int *ids, size_t *ids_size, IntPair pair, int idx) {
int new_ids[MAX_TEXT_SIZE];
size_t new_ids_size = 0;
for (size_t i = 0; i < *ids_size; ++i) {
if (ids[i] == pair.first && i < *ids_size - 1 && ids[i + 1] == pair.second) {
new_ids[new_ids_size++] = idx;
++i; // Skip the next element
} else {
new_ids[new_ids_size++] = ids[i];
}
}
memcpy(ids, new_ids, new_ids_size * sizeof(int));
*ids_size = new_ids_size;
}
size_t find_pair_index(Merge *merges, size_t merges_size, IntPair pair) {
for (size_t i = 0; i < merges_size; ++i) {
if (merges[i].pair.first == pair.first && merges[i].pair.second == pair.second) {
return i;
}
}
return merges_size;
}
void train(BasicTokenizer *tokenizer, const char *text, size_t vocab_size, int verbose) {
size_t num_merges = vocab_size - INITIAL_VOCAB_SIZE;
size_t text_size = strlen(text);
int *ids = (int*)malloc(text_size * sizeof(int));
for (size_t i = 0; i < text_size; ++i) {
ids[i] = (unsigned char)text[i];
}
tokenizer->merges = (Merge*)malloc(num_merges * sizeof(Merge));
for (size_t i = 0; i < num_merges; ++i) {
size_t pair_counts[MAX_TEXT_SIZE * 3];
size_t pair_counts_size;
token_counts(ids, text_size, pair_counts, &pair_counts_size);
size_t max_count = 0;
IntPair best_pair = { 0, 0 };
for (size_t j = 0; j < pair_counts_size * 3; j += 3) {
IntPair pair = { pair_counts[j], pair_counts[j+1] };
size_t count = pair_counts[j+2];
if (count > max_count) {
max_count = count;
best_pair = pair;
}
}
if (max_count == 0) {
break; // No more pairs to merge
}
int idx = INITIAL_VOCAB_SIZE + i;
merge(ids, &text_size, best_pair, idx);
tokenizer->merges[i] = (Merge){ best_pair, idx };
tokenizer->vocab = (unsigned char**)realloc(tokenizer->vocab, (idx + 1) * sizeof(unsigned char*));
tokenizer->vocab[idx] = (unsigned char*)malloc(2 * sizeof(unsigned char));
tokenizer->vocab[idx][0] = best_pair.first;
tokenizer->vocab[idx][1] = best_pair.second;
if (verbose) {
printf("Merge %zu/%zu: (%d, %d) -> %d\n", i + 1, num_merges, best_pair.first, best_pair.second, idx);
}
}
tokenizer->num_merges = num_merges;
tokenizer->vocab_size = INITIAL_VOCAB_SIZE + num_merges;
free(ids);
} At first glance, the code might seem like a huge block and quite complicated, but it’s actually quite straightforward. Here’s a high-level overview of each part:
- Inside the train function , we get to identify the count of each pair of tokens using
token_countsfunction.- the
token_countsgets to iterate over each pair of token in the input text and increment their count based on their presence.
- the
- the most frequent pair is identified.
- they are then merged using the
mergefunction and is stored in the tokenizer. - the vocabulary is update with the new merged token.
Encoding and Decoding
Now lets implement the function that encodes text into token IDs using our trained tokenizer.
void encode(BasicTokenizer *tokenizer, const char *text, int *ids, size_t *ids_size) {
size_t text_size = strlen(text);
*ids_size = text_size;
for (size_t i = 0; i < text_size; ++i) {
ids[i] = (unsigned char)text[i];
}
while (*ids_size >= 2) {
size_t pair_counts[MAX_TEXT_SIZE * 3];
size_t pair_counts_size;
token_counts(ids, *ids_size, pair_counts, &pair_counts_size);
IntPair best_pair = { -1, -1 };
size_t best_idx = 0;
size_t min_merge_idx = SIZE_MAX;
for (size_t i = 0; i < pair_counts_size * 3; i += 3) {
IntPair pair = { pair_counts[i], pair_counts[i+1] };
size_t idx = find_pair_index(tokenizer->merges, tokenizer->num_merges, pair);
if (idx < tokenizer->num_merges && idx < min_merge_idx) {
min_merge_idx = idx;
best_pair = pair;
best_idx = idx;
}
}
if (best_pair.first == -1) {
break;
}
merge(ids, ids_size, best_pair, tokenizer->merges[best_idx].idx);
}
}With the encode function in place, modify the main function to see how it works
int main() {
BasicTokenizer *tokenizer = create_tokenizer();
const char *text = "the sky is blue";
printf("Original text: %s\n", text);
// Encode before training
int ids_before[MAX_TEXT_SIZE];
size_t ids_size_before = 0;
encode(tokenizer, text, ids_before, &ids_size_before);
printf("Encoded IDs before training:\n");
for (size_t i = 0; i < ids_size_before; ++i) {
printf("%d ", ids_before[i]);
}
printf("\n");
// Train the tokenizer
size_t vocab_size = 265;
train(tokenizer, text, vocab_size, 1);
// Encode after training
int ids_after[MAX_TEXT_SIZE];
size_t ids_size_after = 0;
encode(tokenizer, text, ids_after, &ids_size_after);
printf("Encoded IDs after training:\n");
for (size_t i = 0; i < ids_size_after; ++i)
printf("%d ", ids_after[i]);
}
printf("\n");
clean_tokenizer(tokenizer);
return 0;
}After training, the encode function applies these merges to the input text. This results in a more compact representation of the text.
Original text: the sky is blue
Encoded IDs before training:
116 104 101 32 115 107 121 32 105 115 32 98 108 117 101
Merge 1/9: (116, 104) -> 256
Merge 2/9: (256, 101) -> 257
Merge 3/9: (257, 32) -> 258
Merge 4/9: (258, 115) -> 259
Merge 5/9: (259, 107) -> 260
Merge 6/9: (260, 121) -> 261
Merge 7/9: (261, 32) -> 262
Merge 8/9: (262, 105) -> 263
Merge 9/9: (263, 115) -> 264
Encoded IDs after training:
264 32 98 108 117 101 We can see how the blocks one after the other are combined to give a compressed representation of the text.
decode function takes a sequence of token IDs and converts them back into text.
void decode(const BasicTokenizer *tokenizer, const int *ids, size_t ids_size, char *text) {
for (size_t i = 0; i < ids_size; ++i) {
text[i] = tokenizer->vocab[ids[i]][0];
}
text[ids_size] = '\0';
}Conclusion
Implementation of Byte Pair Encoding (BPE) in C highlights its robustness as a method for managing vocabulary size and enhancing language model performance. As the developement of large language models (LLMs) continue to advance, BPE stands out as a foundational tool in the creation of effective tokenizers. It plays a crucial role in breaking down words into meaningful subword units, bridging the gap between raw text and sophisticated language models.
While I do feel that the future may bring even more advanced tokenization techniques, BPE remains a powerful and essential method for the time being. Looking forward to what the future might hold for us.